| Advertisement |
|
|
| Other things |
| |
|
| Web 3.0: When Web Sites Become Web Services |
| Tuesday, March 20, 2007 |
|
|
Today's Web has terabytes of information available to humans, but hidden from computers. It is a paradox that information is stuck inside HTML pages, formatted in esoteric ways that are difficult for machines to process. The so called Web 3.0, which is likely to be a pre-cursor of the real semantic web, is going to change this. What we mean by 'Web 3.0' is that major web sites are going to be transformed into web services - and will effectively expose their information to the world.
The transformation will happen in one of two ways. Some web sites will follow the example of Amazon, del.icio.us and Flickr and will offer their information via a REST API. Others will try to keep their information proprietary, but it will be opened via mashups created using services like Dapper, Teqlo and Yahoo! Pipes. The net effect will be that unstructured information will give way to structured information - paving the road to more intelligent computing. In this post we will look at how this important transformation is taking place already and how it is likely to evolve.
The Amazon E-Commerce API - open access to Amazon's catalog

The Seattle web giant is reinventing itself by exposing its own infrastructure via a set of elegant APIs. One of the first web services opened up by Amazon was the E-Commerce service. This service opens access to the majority of items in Amazon's product catalog. The API is quite rich, allowing manipulation of users, wish lists and shopping carts. However its essence is the ability to lookup Amazon's products.
Why has Amazon offered this service completely free? Because most applications built on top of this service drive traffic back to Amazon (each item returned by the service contains the Amazon URL). In other words, with the E-Commerce service Amazon enabled others to build ways to access Amazon's inventory. As a result many companies have come up with creative ways of leveraging Amazon's information
The rise of the API culture
 The web 2.0 poster child, del.icio.us, is also famous as one of the first companies to open a subset of its web site functionality via an API. Many services followed, giving rise to a true API culture. John Musser over at programmableweb has been tirelessly cataloging APIs and Mashups that use them. This page shows almost 400 APIs organized by category, which is an impressive number. However, only a fraction of those APIs are opening up information - most focus on manipulating the service itself. This is an important distinction to understand in the context of this article. The web 2.0 poster child, del.icio.us, is also famous as one of the first companies to open a subset of its web site functionality via an API. Many services followed, giving rise to a true API culture. John Musser over at programmableweb has been tirelessly cataloging APIs and Mashups that use them. This page shows almost 400 APIs organized by category, which is an impressive number. However, only a fraction of those APIs are opening up information - most focus on manipulating the service itself. This is an important distinction to understand in the context of this article.
The del.icio.us API offering today is different from Amazon's one, because it does not open the del.icio.us database to the world. What it does do is allow authorized mashups to manipulate the user information stored in del.icio.us. For example, an application may add a post, or update a tag, programmatically. However, there is no way to ask del.icio.us, via API, what URLs have been posted to it or what has been tagged with the tag web 2.0 across the entire del.icio.us database. These questions are easy to answer via the web site, but not via current API.
Standardized URLs - the API without an API
Despite the fact that there is no direct API (into the database), many companies have managed to leverage the information stored in del.icio.us. Here are some examples...
Delexa is an interesting and useful mashup that uses del.icio.us to categorize Alexa sites. For example, here are the popular sites tagged with the word book:
Another web site called similicio.us uses del.icio.us to recommend similar sites.
How Web Scraping Works
 Web Scraping is essentially reverse engineering of HTML pages. It can also be thought of as parsing out chunks of information from a page. Web pages are coded in HTML, which uses a tree-like structure to represent the information. The actual data is mingled with layout and rendering information and is not readily available to a computer. Scrapers are the programs that "know" how to get the data back from a given HTML page. They work by learning the details of the particular markup and figuring out where the actual data is. For example, in the illustration below the scraper extracts URLs from the del.icio.us page. By applying such a scraper, it is possible to discover what URLs are tagged with any given tag. Web Scraping is essentially reverse engineering of HTML pages. It can also be thought of as parsing out chunks of information from a page. Web pages are coded in HTML, which uses a tree-like structure to represent the information. The actual data is mingled with layout and rendering information and is not readily available to a computer. Scrapers are the programs that "know" how to get the data back from a given HTML page. They work by learning the details of the particular markup and figuring out where the actual data is. For example, in the illustration below the scraper extracts URLs from the del.icio.us page. By applying such a scraper, it is possible to discover what URLs are tagged with any given tag.
Dapper, Teqlo, Yahoo! Pipes - the upcoming scraping technologies
 We recently covered Yahoo! Pipes, a new app from Yahoo! focused on remixing RSS feeds. Another similar technology, Teqlo, has recently launched. It focuses on letting people create mashups and widgets from web services and rss. Before both of these, Dapper launched a generic scraping service for any web site. Dapper is an interesting technology that facilitates the scraping of the web pages, using a visual interface. We recently covered Yahoo! Pipes, a new app from Yahoo! focused on remixing RSS feeds. Another similar technology, Teqlo, has recently launched. It focuses on letting people create mashups and widgets from web services and rss. Before both of these, Dapper launched a generic scraping service for any web site. Dapper is an interesting technology that facilitates the scraping of the web pages, using a visual interface.
It works by letting the developer define a few sample pages and then helping her denote similar information using a marker. This looks simple, but behind the scenes Dapper uses a non-trivial tree-matching algorithm to accomplish this task. Once the user defines similar pieces of information on the page, Dapper allows the user to make it into a field. By repeating the process with other information on the page, the developer is able to effectively define a query that turns an unstructured page into a set of structured records.
The net effect - Web Sites become Web Services
 Here is an illustration of the net effect of apps like Dapper and Teqlo: Here is an illustration of the net effect of apps like Dapper and Teqlo:
So bringing together Open APIs (like the Amazon E-Commerce service) and scraping/mashup technologies, gives us a way to treat any web site as a web service that exposes its information. The information, or to be more exact the data, becomes open. In turn, this enables software to take advantage of this information collectively. With that, the Web truly becomes a database that can be queried and remixed.
This sounds great, but is this legal?
Scraping technologies are actually fairly questionable. In a way, they can be perceived as stealing the information owned by a web site. The whole issue is complicated because it is unclear where copy/paste ends and scraping begins. It is okay for people to copy and save the information from web pages, but it might not be legal to have software do this automatically. But scraping of the page and then offering a service that leverages the information without crediting the original source, is unlikely to be legal.
But it does not seem that scraping is going to stop. Just like legal issues with Napster did not stop people from writing peer-to-peer sharing software, or the more recent YouTube lawsuit is not likely to stop people from posting copyrighted videos. Information that seems to be free is perceived as being free.
The opportunities that will come after the web has been turned into a database are just too exciting to pass up. So if conversion is going to take place anyway, would it not be better to rethink how to do this in a consistent way?
Why Web Sites should offer Web Services
There are several good reasons why Web Sites (online retailers in particular), should think about offering an API. The most important reason is control. Having an API will make scrapers unnecessary, but it will also allow tracking of who is using the data - as well as how and why. Like Amazon, sites can do this in a way that fosters affiliates and drives the traffic back to their sites. 
The old perception is that closed data is a competitive advantage. The new reality is that open data is a competitive advantage. The likely solution then is to stop worrying about protecting information and instead start charging for it, by offering an API. Having a small fee per API call (think Amazon Web Services) is likely to be acceptable, since the cost for any given subscriber of the service is not going to be high. But there is a big opportunity to make money on volume. This is what Amazon is betting on with their Web Services strategy and it is probably a good bet. |
posted by Sam @ 1:03 AM  |
|
|
|
| Best Practices and Challenges in Building Capable Rich User Experiences: Announcing Real-World Ajax |
| Sunday, March 18, 2007 |
|
|
 It's been nearly a year in the making but I'm finally pleased to announce the release of Real-World Ajax, a massive new compendium of the Ajax spectrum that I've compiled and edited with Kate Allen in conjunction with leading Ajax authors from across the country. While not generally available until later this month, with full availability on March 19th at the AjaxWorld Conference and Expo which I co-chair with SYS-CON Media's Jeremy Geelan, this book marks a significant milestone in the brief history of Ajax, rich user experiences in general, and the growing challenges and opportunities in this space as we continue to witness a tectonic shift in the way Web apps are designed and built. It's been nearly a year in the making but I'm finally pleased to announce the release of Real-World Ajax, a massive new compendium of the Ajax spectrum that I've compiled and edited with Kate Allen in conjunction with leading Ajax authors from across the country. While not generally available until later this month, with full availability on March 19th at the AjaxWorld Conference and Expo which I co-chair with SYS-CON Media's Jeremy Geelan, this book marks a significant milestone in the brief history of Ajax, rich user experiences in general, and the growing challenges and opportunities in this space as we continue to witness a tectonic shift in the way Web apps are designed and built.
The inevitable conclusion: The Web page metaphor is just no longer a compelling model for the majority of online Web applications. We are now rapidly leaving the era where static HTML is acceptable to the users and customers of our software. Combined with the rise of badges and widgets, the growing prevalence of the Global SOA to give us vast landscapes of incredibly high value Web services and Web parts, it's important to note that the use of Ajax is essential to even start exploiting these important trends. Skirting the corners of this phenomenon are also the non-trivial challenges offered up by largely abandoning the traditional model of the browser. Specifically, what happens to search engine optimiziation (SEO), disabled accessibility, link propogation (along with network effects), Web analytics, traditional Web user interface conventions, and more, which are all dramatically affected -- often broken outright -- by the Ajax Web application model?
Some of these questions are answered directly in Real-World Ajax, but many are as yet relatively unanswered in an industry struggling to deal with a major mid-industry change. The tools, processes, and technologies we've brought to bear to build Web applications are going to change a lot, as well as the skill sets. As I wrote in my Seven Things Every Software Project Needs to Know About Ajax , these types of rich Web applications require serious software development skills, particularly as the browser is a relatively constrained environment compared to traditional software development runtime environments like Java and .NET.
Of course, despite this issues -- even because of them -- it is a very exciting time to be in the Ajax business right now. One big reason is that there are few Ajax products with clear market dominance yet and the dozens and dozens of Ajax libraries and frameworks currently available often a very diverse and compelling set of options for use as the foundation of the next great Ajax application. While the Dojo Toolkit is probably the Ajax toolkit with the largest mindshare and lots of industry interest, the big vendors such as Microsoft and their Microsoft's ASP.NET Ajax (aka Atlas) show that the story is just as the first major products from big vendors make their way to market. There's little doubt that we'll continue to see the Ajax market maturing and I'm looking forward to a variety of upcoming improvement to Ajax such as Project Tamarin, the high-speed Javascript engine donated by Adobe to the Mozilla project, the ongoing evolution of OpenAjax, and the 1.0 release of Dojo sometime this year, to name just a few of the exciting things that have the potential to ensure Ajax continues to grow and evolve. |
| posted by Sam @ 10:56 PM |
|
|
|
| Attention Web 2.0 Start-Ups: Party May Be Ending |
| Friday, March 16, 2007 |
|
|
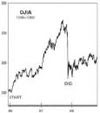 Who says Wall Street firms are always bullish? According to Reuters, Merrill Lynch published a report today suggesting that housing market woes could drag the economy into a recession and that, if it does, investors can expect a drop in the S&P 500 of at least 30% from the peak. Even if there is no recession, and the market just does a head-fake, we should expect a drop of about 20%. Who says Wall Street firms are always bullish? According to Reuters, Merrill Lynch published a report today suggesting that housing market woes could drag the economy into a recession and that, if it does, investors can expect a drop in the S&P 500 of at least 30% from the peak. Even if there is no recession, and the market just does a head-fake, we should expect a drop of about 20%.
How will a public-market stumble affect Web 2.0 start-ups? The same way the market crash in the fall of 2000 did, albeit to a lesser extent:
Money will get harder to raise. (Because VCs will be feeling pressure from their clients, and exit valuations will be lower).
Financing and exit valuations will be lower. Because the stocks of acquirers and comparably public-market companies will be lower.
Investors will get impatient for start-ups to develop businesses instead of "products" and "communities."
The growth rate of online advertising will slow dramatically. In tough times, advertising is one of the first expense lines to get cut (by big businesses and small). What's more, some start-ups that are currently buying advertising will cut back or cease to exist.
In short, being a Web 2.0 entrepreneur or employee may soon get more difficult and less fun. Hit the bids while you can! |
| posted by Sam @ 8:33 AM |
|
|
|
| Web Site Usability Checklist |
| Thursday, March 1, 2007 |
|
|
Web Site Usability Checklist 1.0
Site Structure:
· Does everything in the site contribute to the purpose of the site?
· Is the overall site structure confusing, vague, or seemingly endless?
· Is the overall site structure capable of being grasped?
· Does it have definite boundaries or does it seem endless?
· Does the user have some feedback about where he is in the site?
· Is the site too cluttered (information overload) or too barren (information underload)?
· Is the most important content displayed in a more PROMINENT manner?
· Are the more frequently used functions more PROMINENT on the site?
· Does the site use technologies that lend themselves to the web (such as graphics, sound, motion, video, or other new technology)?
· Does the site use advanced technologies only in manner that enhances the purpose of the site?
. Does the site have too many useless bells and whistles?)
· Is the site so aesthetic (or comedic, etc) that it distracts from the overall site purpose?
· Is it clear to the novice how to move within the site?
· Is the site so narrow and deep that the user has to keep clicking through to find something, and gets lost?
· Is the site so broad and shallow that the user has to keep scrolling to find something?
Content:
· From the viewpoint of the user, is the site full of trivial content or vital content?
· Is the overall purpose of the site muddy or clear?
Usual purposes:
1) to exchange money for a product or service or
2) educate about someone or something.
· Does the site use words, abbreviations, or terms that would be unfamiliar to a novice user?
· Does part of the site establish the creditability, trustworthiness, or honesty of the owners when necessary?
· Does the site allow for suggestions and feedback from the users?
· Does the site allow for the users to communicate with each other via chat rooms or internal newsgroups thus creating a sense of community?
Readability:
· Is the text easy to read?
· Does the font style contribute to the purpose of the site without losing readability?
· Is there sufficient contrast between the text and the background?
· Is there too much contrast between the text and the background?
· Are the characters too small? Too large? Does the novice know how to change their size for easier reading?
· Do the colors enhance the user's experience while not sacrificing text legibility?
Graphics:
· Do the graphics contribute to the overall purpose of the site or distract from it?
· Do the images load quickly or does the user have to wait impatiently?
Speed:
· Is it hard to locate a target item, causing the user to lose patience and leave?
· For a large-content site, is there an internal search engine?
· Does the user have to go through too many steps to accomplish a task? (buying, joining, registering)?
· Does an expert user have options that allow them higher speed?
· Does the site designed using generally accepted human factors principles? (feedback, transfer of training, natural mapping, movement compatibility, cultural compatibility, logical compatibility, etc.) |
| posted by Sam @ 9:50 AM |
|
|
|
|
| About Me |
Name: Sam
Home: New Delhi, Delhi, India
About Me: I am a 29 year old Web Analyst from Bihar, INDIA. I started my career as a part time Lab assistant in Webcom Technologies, USA in Pitampura at an age of twenty while in First Year. I am fortunate that my first experience in professional world was in such a friendly and informal environment.
I have taken a keen interest in internet technologies since 1999 when I began creating websites for friends and family during my time at school. Using a trial and error method I quickly mastered HTML and using my existing graphics skills and eye for detail I began developing the foundations to my career. from last 5 years, I took the position of Project Manager at V-Angelz Technologies.
Since being in this position I have had the chance to further improve on my Usability, Accessibility, SMO and Business Development skills by producing several dynamic websites for the group and taking sole responsibility for the re-building and on-going development of the CMS, ERP and CRM System.
See my complete profile
|
| Previous Post |
|
| Archives |
|
|
| Links |
|
|
| Powered by |

|
|










